
엘라스틱 키바나에 접속하여 아래 하단에 Upload a file을 눌러 csv 파일을 적재한다.

excel파일이면 csv파일로 변형해서 넣는다. 단, csv 파일 변형시 UTF-8 (쉼표로 구분)을 선택해야 양식에 맞게 적용시킬수 있다. 여기서 Number of lines을 한 컬럼이라고 부르는데 노출되는 데이터양은 1000개 뿐이다. 추가로 설정해서 더 많은 데이터를 받을 필요가 있다.

Type은 date형, Integer형 등등 자동으로 인식됐고 Documents도 잘 나와있다. 여기서 Document는 한 컬럼을 의미한다.

노출되는 데이터 양이 1000이므로 늘려주자 [Override settings] 선택한 후 Number of lines to sampled을 10000으로 바꿔준다. [Has haeder row]는 첫 번째 데이터 컬럼을 필드명으로 쓰겠다.
한글보다는 영어가 인식하기 편하므로 날짜 등은 date등 영어로 바꿔준다.

Name이 모두 영어로 바뀌었고 Document수가 모두 잘 나왔다. import를 눌러 다음으로 진행한다.

클라우드내 같은 사용자와 Index name이 겹치지 않도록 이름을 유니크하게 적어준다.

여기서 csv 파일의 한줄의 document, csv 파일 하나가 Index라고 개념을 잡아보자.
index pattern = 이름을 가지고 데이터를 묶어주는 것.
여기서는 키바나를 이용해서 시각화하려면 꼭 필요한 과정이다.
모두 확인했으면 [View index in Discover]으로 넘어간다.
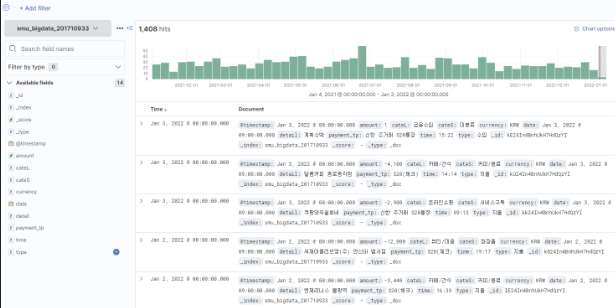
오른쪽 상단을 눌러서 날짜, 시간을 설정하여 원하는 데이터를 불러올 수 있다.
왼쪽 상단의 [Search]를 통해 쿼리 선택 가능하다. [Add filiter]를 통해 만들어놓은 인덱스를 선택할 수 있다.

만들어놓은 패턴을 한 번에 확인할 수 있다.
'Kibana > kibana 시각화기능' 카테고리의 다른 글
| 6. Tag Cloud (0) | 2022.07.13 |
|---|---|
| 5. Matric (0) | 2022.07.13 |
| 4. DashBoard, TSVB (0) | 2022.07.13 |
| 3. Table (0) | 2022.07.13 |
| 2. Lens (0) | 2022.07.13 |