
- PUT라인에 커서를 올리고 ctrl + enter로 실행해본다.
- 에러없이 잘 진행됐으면 오른쪽에 이와같이 출력된다.


- 두 번이상 실행하면 에러가 뜬다. 이미 PUT을 했기에 중복이 안된다는 것이다.
- 이땐 아래처럼 DELETE를 이용해서 삭제하고 다시 정의해주면 해결된다.

- GET을 통해 출력이 잘 되는지 확인한다.
- 오른쪽에 잘 나온다.
4. TEST

- 잘되있는지 테스트해보자.
- GET이후 /_analyze를 이용한다. 이를 이용하면 token이 입력한 그대로 데이터그 자체로 토큰이 만들어진다.
- 이것과 꼭 일치한 것만 검색한다. 라는 의미이다.

- dtail뒤에 detail.raw를 쓰면 오른쪽과 같이 내부에서 자동적으로 토큰을 나눠준다.
- 여기서는 3개의 토큰으로 나뉘어 생성된다.
- 찾을 택스트는 : 와같이 적어준다. 그러면 알아서 나뉜다!

- detail뒤에 위에서 정의한 standard_stem을 적어준다. 그러면 정의한대로 ()등 정의한 불용어들이 삭제되서 나온다.
- 하지만 여기서 문화비로 나와야하는데 비를 명사로 인식해서 나뉘어서 나온다.
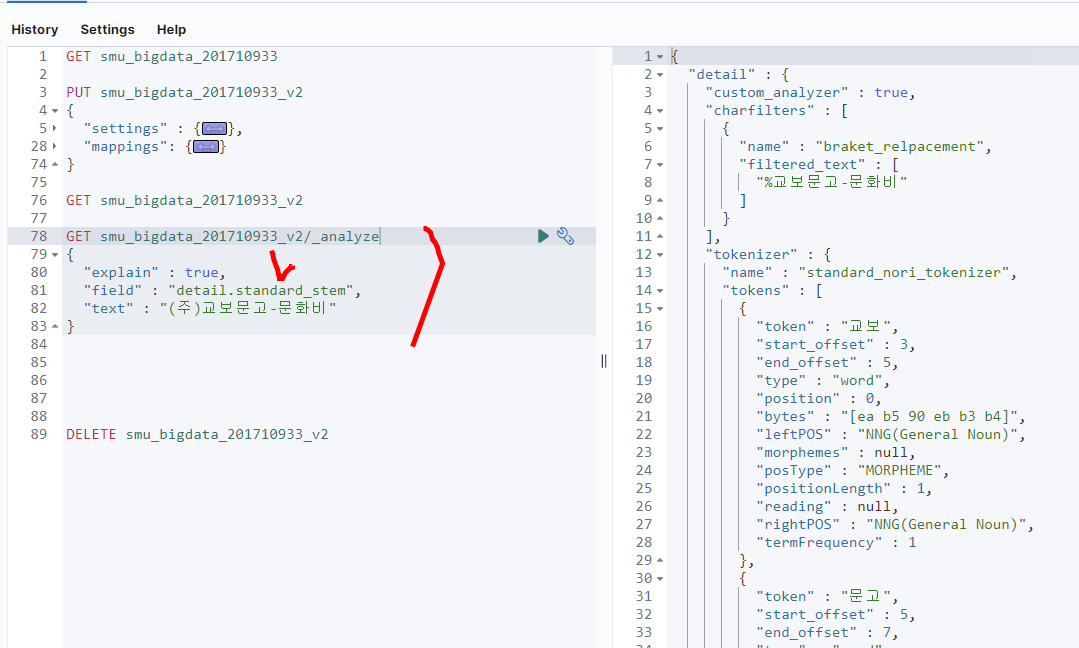
- “explain” : true는 결과가 어떻게 처리되고 어떤 형태인지 상세하게 모두 나오게한다.
- 오른쪽의 morphemes같은 경우는 품사이다. 이처럼 자세하게 나온다.
- 지금까지 type에 따라, token의 출력형태, analyzer의 적용 유무에 따라 어떻게출력되는지 확인해봤다.
- noritoken에서 제공하는 것을 그대로 사용하면 ‘우아한형제들’의 경우 우아, 한,등으로 짤려버린다. 그러면 원하는 검색결과나 나오지 않는다.
- 따라서 하나하나 추가로 같다라고 인식해줘야 한다. 즉, 동의어 필터를 적용해야한다.
- 이뿐만 아니라 사용자 정의사전을 추가할 수 있다.
'Kibana > kibana 시각화기능' 카테고리의 다른 글
| 10. Dev Tools(Tokenizer, Synonym) (0) | 2022.07.13 |
|---|---|
| 8. Dev Tools(Setting & Mapping) (0) | 2022.07.13 |
| 7. Maps (0) | 2022.07.13 |
| 6. Tag Cloud (0) | 2022.07.13 |
| 5. Matric (0) | 2022.07.13 |