- 데이터 전처리 진행(불용어 제거, 맞춤형 검색, 수정, 정재)
1. 데이터 검토 및 Mapping

- 홈에서 메뉴를 클릭하고 Management의 Dev Tools에 들어간다.
- 미리 만들어두었던 Index Pattern을 GET으로 불러온다. 그 이후 Ctrl + Enter로 실행한다.
- 그러면 오른쪽에 쿼리를 쭉 살펴볼 수 있다.
- 왼쪽 화살표를 이용해도 좋고, 최소화 하고자하는곳에 커서를 올리고 Alt + 0을 누르면 축소시킬 수 있다.
- Index Pattern에는 크게 ‘mapping’ 와 ‘settings’쿼리가 존재한다.
- ’mapping’하위 필드는 ‘_meta’, ‘properites’ 등이 존재한다.
- ’properties’를 클릭해보면 각각의 document들이 가지고 있는 필드를 볼 수 있다.
- timestamp, amount 등등.. JSON형식으로 이루어져 있다.
- 하나하나 확인해보면 만들어둔 Index Pattern의 Type을 검토할 수 있다.
- mappings의 내용을 확인해봤다.
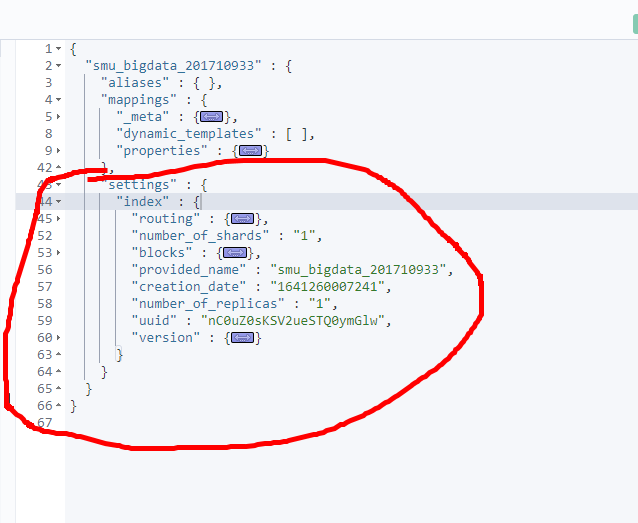
- ‘settings’를 살펴보면 Index에 관련된 설정들이 담겨있다.
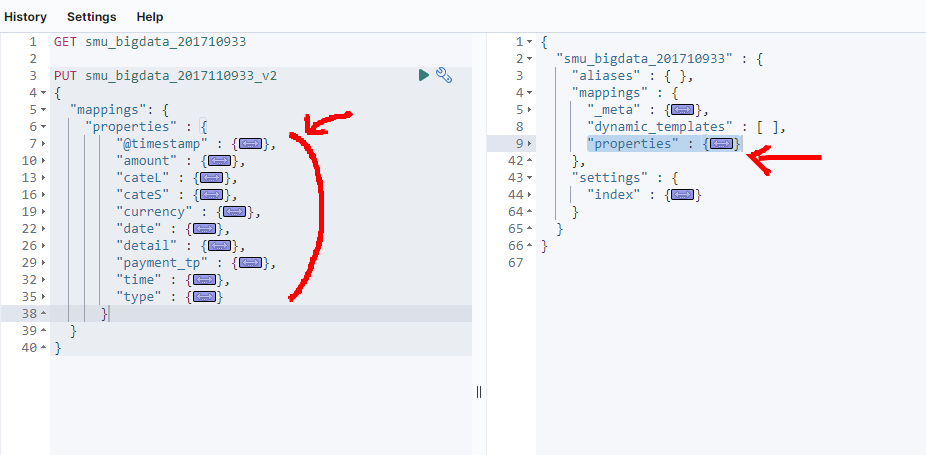
- GET말고 PUT으로 쿼리를 정의해줄 것이다.
- PUT 이름_v2를 정의해주고 매핑 형식에 맞게 ‘mappings’문법을 하나하나 적어준다.
- 그 이후 GET으로 확인했던 오른쪽의 ‘properties’부븐을 그대로 복사해서 ’mappings’하단에 붙여넣기한다.
- 그리고 보기좋게 alt + 0을 해준다.
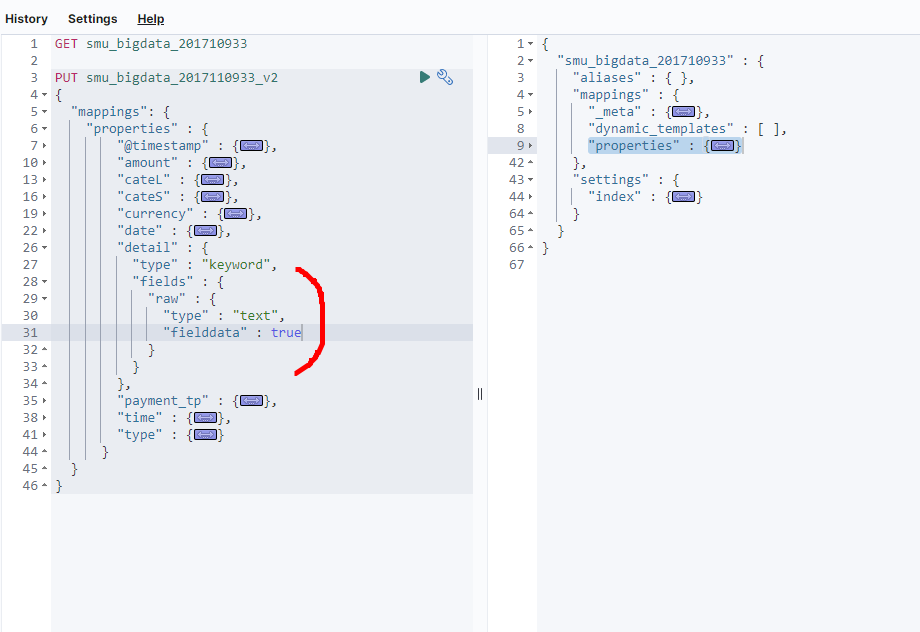
- 왼쪽에서 ‘detail’부분을 열고 ‘keyword’ 뒤를 이와같이 넣어준다.
- 다시 축소화시켜주면 매핑은 끝
2. settings
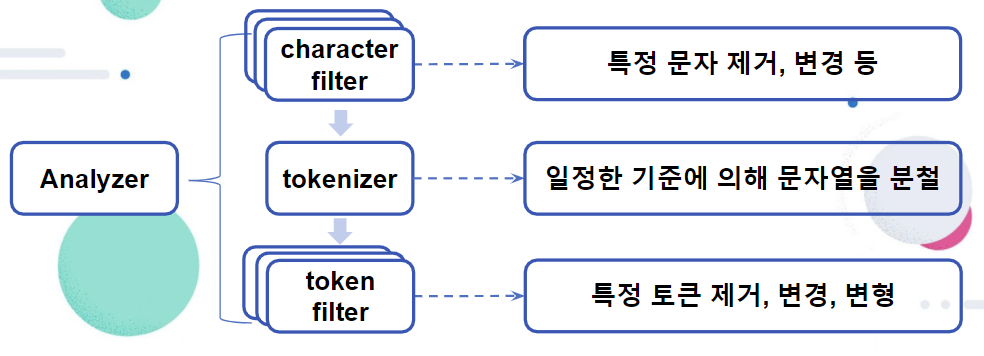
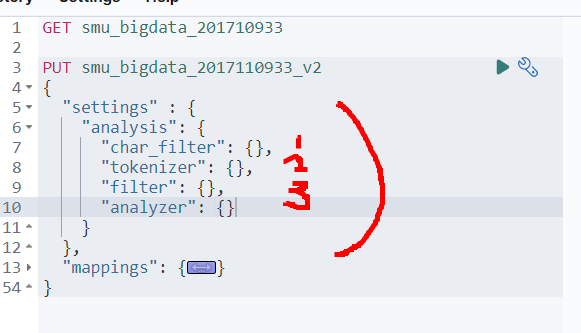
- setting의 analysis부분을 설정해주겠다.
- analysis는 3가지가 있는데 이 기능을 모두 시행하기 위해 3가지 모두를 정의하겠다.
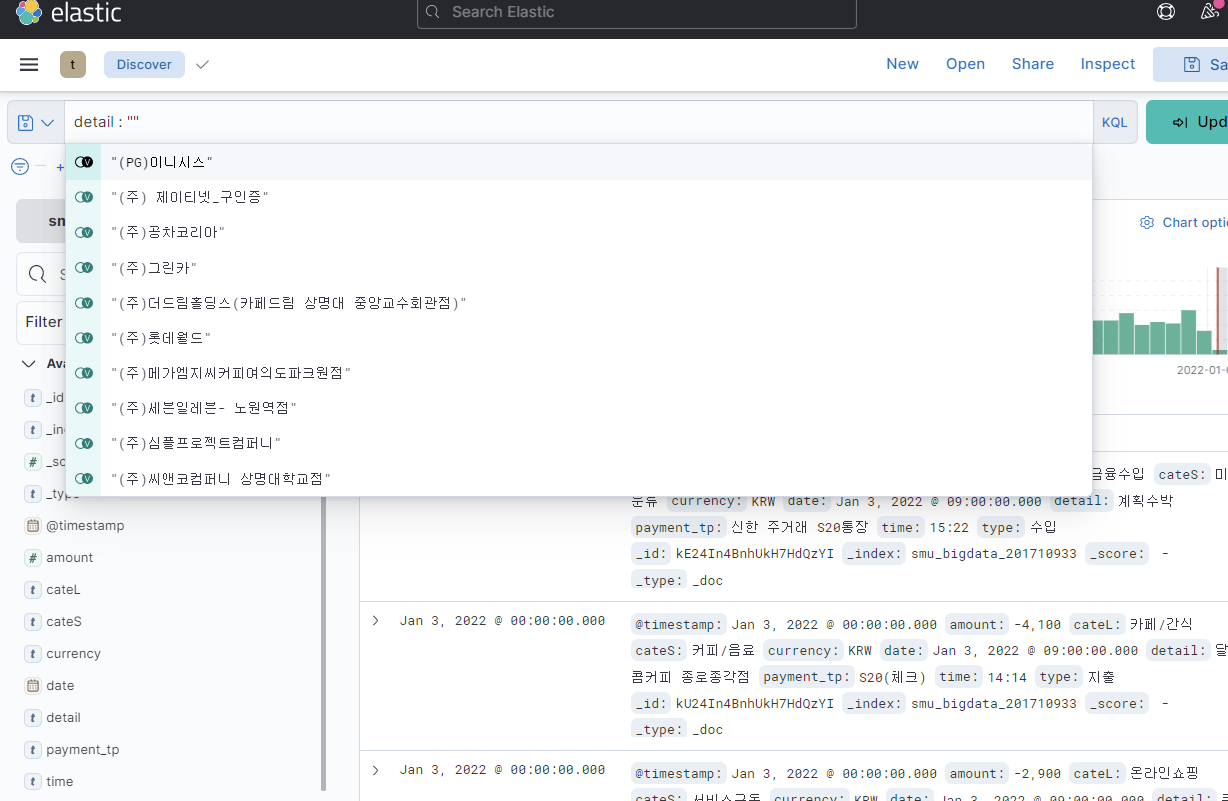
- [Discover]로 돌아가서 왼쪽 상단에 detail : “”를 검색해본다.
- detail은 csv파일의 컬럼명이 “내용”을 Index pattern을 만들면서 detail로 바꿔줬기에 detail을 적어서 내용을 확인한다.
- 이렇게 검색하면 detail의 모든 항목을 보여주는데 여기서는 (주) 등 필요없다.
- 이처럼 필요 없는 불용어를 제거해보자.
- charater_filter에서 이를 수행할 수 있다.
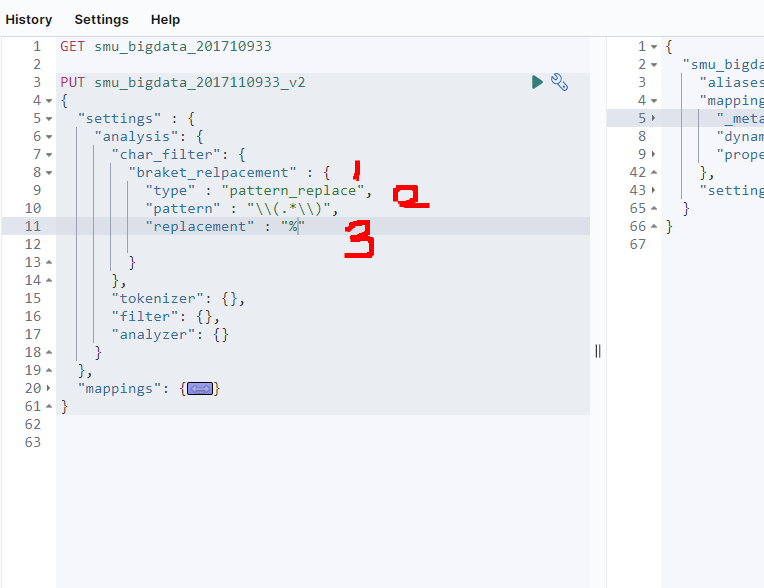
- 이렇게 문법을 한 번 적어보자. 필터이름은 아무거나 써도 된다. 여기서는 쉽게식별할 수 있게 braket_replacement라 정의한다.
- type은 pattern_replace로 선언한다. 사용할 수 있는 필터는 HTML, Mappin, pattern_replace이 3가지 패턴 필터가 있다.
- 우리는 pattern_replace 패턴 필터를 쓰겠다.여기서 역슬레시를 추가하는 이유는 이 뒤 문자부터는 하나의 패턴으로 인식하기위해서 이다.
- ex) \\d → 숫자, \\w → a~zA~z, 0~9를 하나의 문자로 표현한다.
- ex) \\(\\) → \\ 자체를 인식하겠다. 여기서 .은 모든 문자를 나타내고 *은 1개 이상을 나타낸다.
- replacement = 바로 위의 패턴에서 정의된, 해당되는 문자열을 이와같이 바꾸겠다. “ “로 정의하면 잘 바뀌었는지 보기 어려우므로 %를 넣겠다.이제 Character filter를 정의했다.
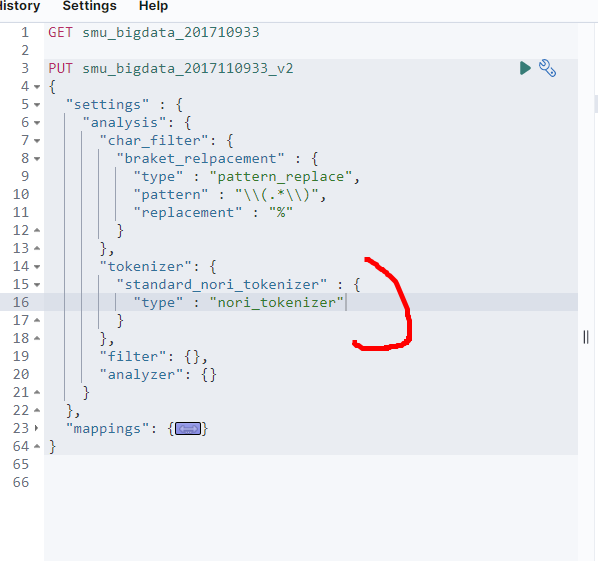
- tokenizer을 만들어보자. 여기서도 사용하고 싶은 식별자 이름을 적어주면 된다.
- 여기서는 standard_nori_tokenizer로 정의했다
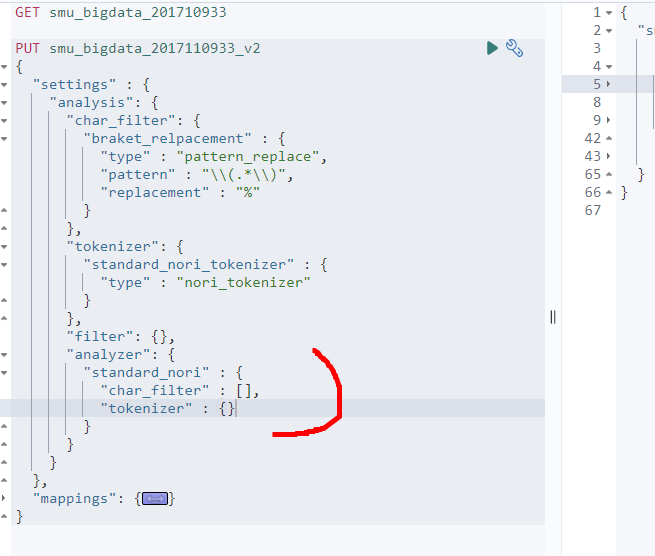
- anlayzer부분을 정의해보자.
- char_filter은 배열형식이므로 []로 선언, 나머지는 {}로 선언한다.
- 위에 char_filter, tokenizer, filter 3개를 이 부분 안의 analyzer에 적어준다.
- 근데 filter은 아직 따로 내용을 선언 안했으므로 이따 쓰겠다.
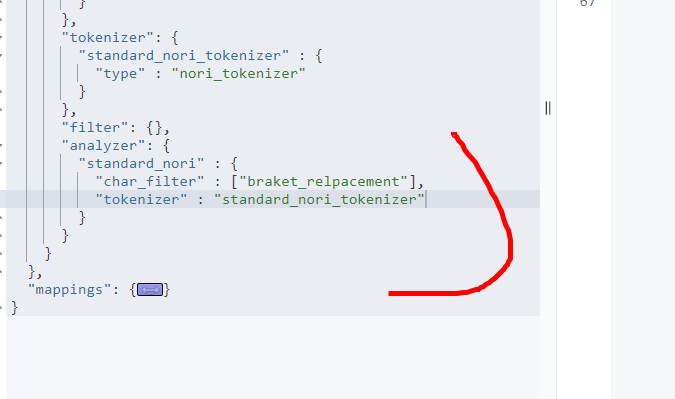
- 처음 선언했던 char_filter를 넣어준다. 변수명을 [ ]안에 넣어주면 된다.
- tokenizer도 선언한 변수를 안에 넣어준다.
- 이렇게 되면 하나의 analyzer을 만들었다.
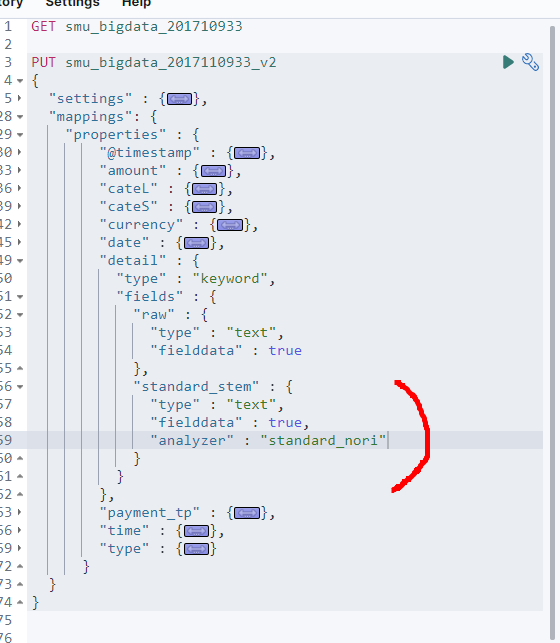
- 이제 ‘settings’를 접고 ‘mappings’을 펼쳐보자
- standard_stem이라는 하위 필드를 하나 정의해준다.
- 그 하위 필드에 analyzer도 적용해준다. standard_nori는 위 ‘settings’에서 정의했던 것이다.
- 그럼 fields필드 안에 ‘raw’, ‘standard_stem’이라는 하위 필드 2개가 생성되었다.
- 이렇게 setting을 끝냈다.
'Kibana > kibana 시각화기능' 카테고리의 다른 글
| 10. Dev Tools(Tokenizer, Synonym) (0) | 2022.07.13 |
|---|---|
| 9. Dev tools(GET, PUT, DELETE) (0) | 2022.07.13 |
| 7. Maps (0) | 2022.07.13 |
| 6. Tag Cloud (0) | 2022.07.13 |
| 5. Matric (0) | 2022.07.13 |