가용성(Availability)
- 생산적인 목적으로의 시간 사용 비율
- 컴퓨터 시스템에서는 서비스가 가능한 기간
고가용성(High Availability)
- 장애를 최소화되도록 관리하거나 예상된 다운타임을 최소화함으로써 서비스의 손실을 줄일 수 있는 행위
- 하드웨어 고장, 서버 죽어도 서비스가 되도록 구성

- 서비스가 잘유지되려면 한 곳 이라도 제 역활을 잘 해야한다.
- 구간구간마다 가용성을 높일 수 있는 아키텍처를 구성해야 한다.
- 관점은 2개가 존재한다.
- 유지 관점 : 서비스가 중단되지 않고 성능을 유지
- 접근 관점 : 언제든지 서비스에 대한 접근/접속 및 사용될 수 있는 능력
- MTTF (Mean Time To Failure, 평균 고장 시간) : 장애 나기 전까지 시간들의 평균
- MTBF (Mean Time Between Failure, 평균 고장 발생 간격): 장애 복구부터 다음 장애 시점까지 평균 연속시간
- MTTR (Mean Time To Repair, 평균 복구 시간) : 시스템을 정상 상태로 돌려놓기 위해 소비하게 되는 평균 시간
가용성(%) = ( MTBF / ( MTBF + MTTR) ) * 100(%)
여러가지 이중화가 존재한다.

네트워크 이중화

스토리지 채널 이중화
- 스토리지 FA Port, SAN 스위치, HBA 등을 다중화 구성하여 확보한다.

- SAN 스위치 포트 장애시, 채널 Failober S/W를 통해 지속적인 서비스 제공 ( 평소에는 로드벨러싱 수행)
- SAN 스위치 포트는 고속의 대역폭을 제공함으로써 안정적인 데이터 서비스를 지원
- 서버 및 스토리지 채널의 다중화를 통해 단일 채널의 장애시에도 정상적인 서비스 수행
- SAN 스위치의 관리 모듈을 통해 포트 별 상태 모니터링 및 장애 감지
- 장애가 발생한 HBA 모듈 교체에 의한 신속한 장애 복구
Multipath
- 스토리지 채널 이중화를 위해 2개 이상의 채널을 서버와 연결하면, 서버에서는 각 채널별로 다른 디스크로 인식됨
- 이를 가상 디바이스로 묶어서 이중화를 구현하는 S/W
업무 단위 : 클러스터링
클러스터링(Clustering)
- 2대 이상의 독립된 시스템들이 모여서 각각의 자원을 공유 및 활용하여 한 시스템의 장애시에도 최소의 시간으로 서비스를 지속하기 위한 개념
- 서버이중화 개념
다음과 같은 방법으로 클러스터링을 진행할 수 있다.
- Fail - Over
- HA 클러스터링 (전통적)
- 로드밸런싱
- 공유 프로세싱
HA 클러스터 구성

- 대표적인 아키텍처이다.
- 스토리지는 공유 디스크가 필요하며
- active 서버에서 공유 디스크를 마운팅 하다가 장애시 Standby 서버 B에서 이용한다.
- Heartbeat가 있다 케이블에 다이렉트로 연결되어있어 패킷을 서로 주고받아 죽었는지 확인(심장 두근두근)
- 양쪽 서버는 모두 ip를 가지고 있고 서비스를 올린 서버는 서비스 ip를 추가로 올려서 사용한다.
- 공유 디스크에 모두 가져와 할당하고 서비스 ip를 가져온다 이렇게 마운팅!!!
RHEL Pacemaker

- Fencing N/W를 구성해야함 (이중화된 트위치)
- HeartBeat 역할을 하며 하드웨어의 IPMI 포트에 연결되어 있다.
- IPMI는 OS관계없이 H/W Shutdown 시킬 수 있다.
- Split Brain을 대피한 Fencing Network
Q. Split Brain이 뭔가요!!?
A. 클러스터 노드간의 네트워크가 단절되었을 때 모든 노드가 살아있으면서 자기가 주라고 생각하는 경우, 이때 한 곳을 Power Off시켜줘야 합니다!!
DBMS의 Active - Active 구성 (DBMS A-A 클러스터 구성)
- 대표적인 벤더의 A-A(Active - Active) 구성은 Shared Disk Concurrent Write기반으로 구성
- 조금이라도 서버가 중단되는 것을 불가한다!!!

- 예시 참고..
DBMS의 데이터를 복제해서 Active - Active 구성하는 방법도 있다.
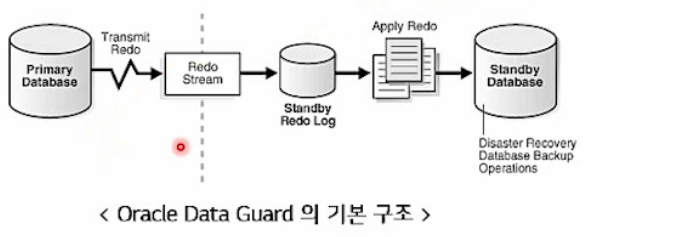
- DB를 위한 스토리지 용량이 필요하다.
이중화 구성을 잘못한 예시
- 서버는 이중화되어 있지만 Client에서 이중화 구성에 맞지 않게 설정되어 서버 장애 시 정상적으로 서비스 불가

- 4동 MES DB는 MS SQL AlwaysOn으로 이중화 되어 있고 Active 서버에서 서비스 수행중
- 해당 서버는 FA망, OA망 2개의 네트워크 대역을 보유하고 있고, Standby서버로 이전 가능한 IP대역은 FA망
- MES AP 이외의 접속 대상은 장애시 Standby서버로 이전 불가능한 OA망 IP를 사용하는 것으로 확인
- 클러스터가 들고다니는 서비스 IP(FA망) 에 연결해서 사용해야함
- 4동 MES AP는 서비스 IP로 잘 연결했지만
- 나머지 4개는 실제 서버 IP망에 연결되어 있다!! (잘못연결한 거)
<장애 일어날 때>
- Active서버의 장애 시 Standby서버로 가상 IP(FA망)를 전이 후 Standby서버에서 정상적으로 서비스를 수행
- 가상 IP (FA망)로 접속하게 설정한 4동 MES AP는 실패를 감지하고 재접속하여 정상적으로 업무 수행
- 나머지 OP망 IP를 사용하는 서버는 정상적으로 업무 수행 불가
클러스터는 여러 개의 시스템들이 하나의 시스템을 이룬다.
하나의 시스템을 가상 서비스IP가 지목되는데 연결될 서버는 가상 서비스 IP에 연결되어야 한다.
추후 여러 개의 시스템 중 하나가 문제 생겨도 자연스럽게 가상 서비스 IP는 정상작동인 시스템으로 연결되지만 위 상황처럼 직접 OP망의 IP로 연결하면 그 시스템이 장애가 발생하면 사용할 수 없다!!
업무 단위 : 로드밸런싱
L4 스위치 로드밸런싱
- 웹 서버의 경우 일반적으로 L4 스위치를 이용하여 고가용성 시스템을 구현

- 이중화 중에 로드밸런싱을 봐보자!!
브라우저 주소를 치고 들어가면 DNS가 주소에대한 IP를 알려준다. L4에 대한 서비스 주소를 알려준다는 거다~~
L4에 접속을하고 L4는 진짜 웹서버에게 로드밸런싱을 진행하는 것!!!
L4 스위치 로드밸런싱 방식
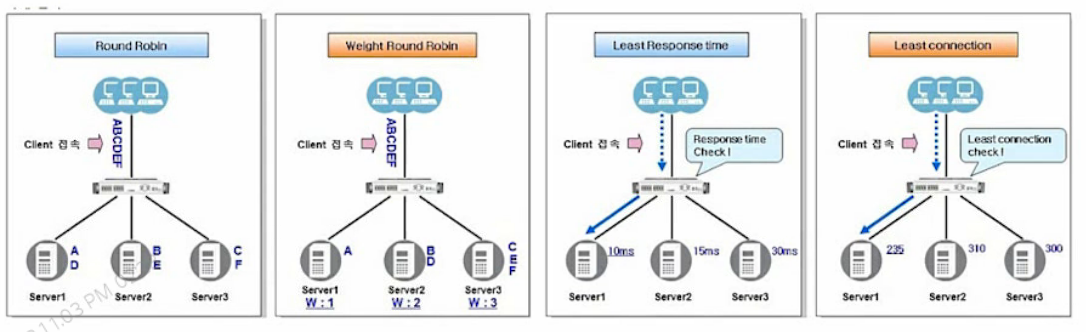
| 로드밸런싱 방식 | 설명 |
| Round Robin | 세션을 순차적으로 맺음 |
| Least Connection | Open Session이 가장 적은 서버와 세션 맺음 |
| Response Time | 응답시간이 빠른 쪽으로 많은 세션을 보냄 |
| Hash | Source IP를 기반으로 서버를 선택 같은 사용자의 요청은 항상 같은 서버로 연결 |
L4 SLB Proxy Mode & DSR (Direct Server Return)
| 방식 | 설명 |
| SLB | Response Packet이 L4를 거쳐서 Client에게 전달 (L4 부하 !!!!!) L4와 서버는 다른 네트워크 대역에 있어도 무방 |
| DSR | Response Packet이 서버에서 바로 Client에게 전달 (L4 부하 경감) L4와 서버가 같은 Network 대역에 있어야 함 서버의 Loopback Adapter에 L4 VIP 추가 필요 |

- SLB는 L4 스위치 - 서버 - L4 스위치 - 서버 - 사용자
- 부하가 생기지만 다른 네트워크여도 구성 가능!!
- DSR L4 스위치 - 서버 - 사용자
- 같은 네트워크 대역에 있어야 한다!!
- 조금 많은 설정을 진행해야 한다...
업무 단위 : 데이터 가용성 (1/2)
스토리지 복제
- 1) 스토리지 복제를 통한 데이터 가용성 확보

스토리지 주센터에서 내부복제, 외부로 복제도 있다!!
로컬의 스토리지에 에러나도 데이터는 지키게따!!
LUN단위이며 항상 원본, 복제와 꼭 똑같아야 한다!!
스토리지가 부족해 추가 할당하면 복제도 할당해야한다. (안되면 복제 다 안돼~~~)
- 2) Sync 방식과 Async 방식의 복제 방식
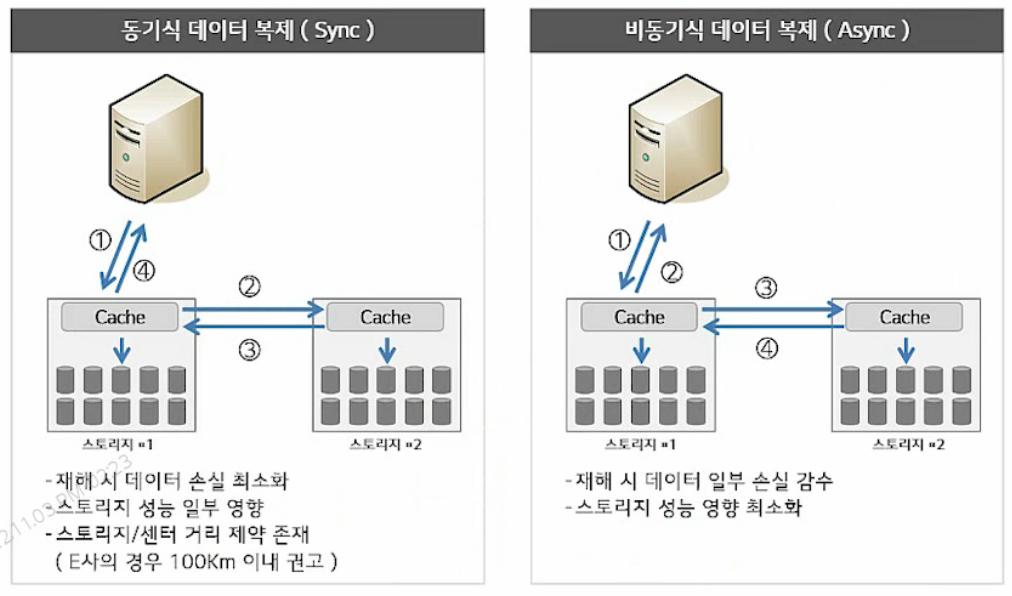
| 동기식 | 데이터 받고 야!! 데이터 써!! 오케이 썻어! 확인서 가져가! 확인서 받고 본체로 고!! |
| 비동기식 | 데이터 받고 야!! 데이터 쓰셈!! (던져주기만 함) 본체로 고!! |
- 동기식은 스토리지 성능은 안좋아지되 데이터 유실 가능성이 적다!!
- 비동기식은 스토리지 성능은 지키되 데이터 유실 가능성이 존재한다!! (뒤도 안돌아보고 오므로)
재해복구센터 (DR센터 구축방식)
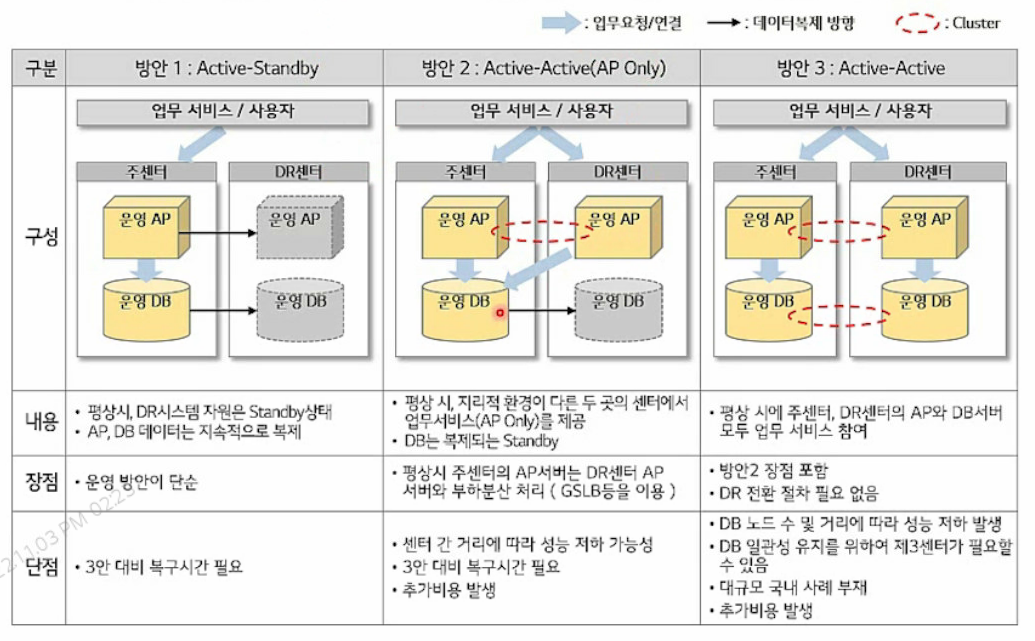
- 방안 1 : 평상시엔 DR센터 놀고 재해시 올려서 씀
- 방안 2: 두가지가 있다.
- AP 영역(WEB / WAS)만 A-A로 구성하는 방식
- WEB 구간은 GSLB등을 서비스/사용자 접속처리를 분배
- WAS 구간은 세션동기화 등 요건이 있다면 IMDG를 사용하고 복제,동기화 검토 필요
- AP 영역(WEB / WAS)만 A-A로 구성하는 방식
- 방안 3: DR에서도 DB를 운영하는 방식
- DB의 경우 스토리지 가상화 기술 등을 이용하여 양쪽에서 RW를 구현
- CDC를 통해 양방향 동기화 가능하나 비동기방식으로써 직접 코딩해야 함
- 센터간 거리, DB 노드 수에 따라 성능 저하의 이슈를 가지고 있어 캐쉬를 적극적 할용!!
업무 단위 : Cloud 설계의 변화
Cloud 아키텍처에서의 이중화 구성
- 확정성을 고려하여 수평적으로 늘어나는 것을 고려해야 한다.
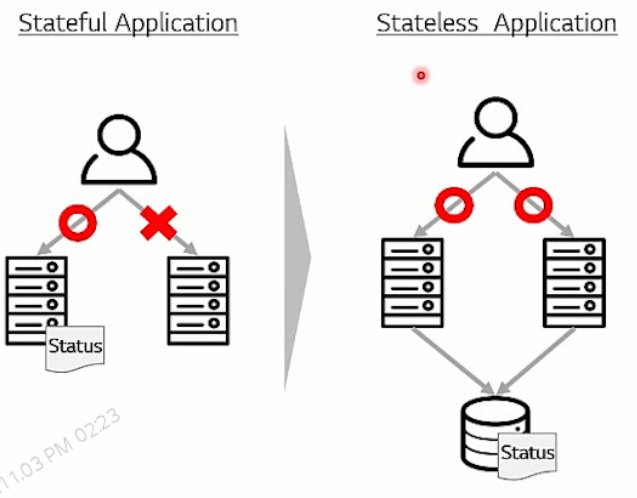
상태 정보를 스케일 인, 아웃으로 저장하지 말고 외부의 다른 곳에 저장해서 사용해야 한다!!! (Stateless)
분산 DB, DB 복제

왼쪽에서 오른쪽으로 변화중
마스터 DB있고 Slave DB를 만들어 분산한다!!
마스터는 읽기 쓰기!! (에러시 Slave중 1개가 마스터!!)
Slave는 쓰기만!!
Cloud 이중화 예시

- 멀티 가용영역으로 이중화를 진행함
- ELB(로드벨런서)로 WEB, WAS 이중화가 되어있다.
- DB가 마스터 및 Slave로 이중화 및 분산되어 있다.
'Technical Architecture > 시스템 아키텍처' 카테고리의 다른 글
| 데스크탑 가상화란?(4) (0) | 2022.12.27 |
|---|---|
| 가상화(3) 쿠버네틱스란?(Kubernetes) (0) | 2022.12.27 |
| 가상화란? (0) | 2022.12.27 |
| 확장성 (0) | 2022.12.27 |
| 아키텍처 개요 (2) | 2022.12.27 |